Xiaomi MiMo Partners with TileRT | 1T Model Breaks 1000 tokens/s Output Speed for the First Time
Xiaomi MiMo-V2.5-Pro-UltraSpeed: In all martial arts under heaven, only speed prevails
From the first sports car of the internal combustion engine era to supersonic flight breaking the sound barrier, humanity's thirst for speed is ingrained in our genes.
The speed of AI inference also determines the boundaries of intelligence. When the model is fast enough, it is no longer just a tool that "waits for results" but becomes an extension of your thinking - real-time response, instant iteration, and seamless collaboration.
Today, MiMo × TileRT jointly announced: The UltraSpeed mode of Xiaomi MiMo-V2.5-Pro enables the output speed of flagship models with trillions of parameters to exceed 1000 tokens/s for the first time.
How fast is 1000 tokens/s exactly:
Limited-time opening · Application-based experience
MiMo-V2.5-Pro-UltraSpeed API is now available for synchronization, offering a limited-time trial price, priced at 3 times that of MiMo-V2.5-Pro, while providing approximately 10 times the output speed improvement!3 times the price increase, 10 times the output experience. (Only API experience is supported, Token Plan is not supported for the time being)
This MiMo-V2.5-Pro-UltraSpeed will be open for a limited time on an application basis. Users whose applications are approved can access the API for a limited time to experience it, with the time limited from June 9 to June 23, 2026, 23:59.
Within 12 hours after the release of MiMo-V2.5-Pro-UltraSpeed on the X (Twitter) platform last night, more than 3,000 enterprises and their developers applied for trial access to the UltraSpeed API, with industry categories covering law, finance, hospitality, telecommunications, logistics, internet, culture and media, automobile manufacturing, etc.
👉 Application Entry: https://platform.xiaomimimo.com/ultraspeed
Due to limited inference resources, the number of trial slots for this time is limited. After submitting an application, we do not guarantee the timeliness of review or the review pass rate; we will prioritize the review of enterprises and professional developer scenarios with real business needs. If you have large-scale commercial needs related to UltraSpeed, please feel free to contact business-mimo@xiaomi.com.
💬 Chat Experience (Limited-time Free)
Users who pass the review can also obtaintime-limited freeChat experience (valid within a two-week open window), with the experience entry:https://ultraspeed.xiaomimimo.com
To ensure the quality of experience and fairness of use under resource-constrained conditions, the trial service rules are as follows: Each account can successfully enter the queue up to 10 times per day; the maximum duration of a single session is 30 minutes; if a session remains idle for more than 5 minutes, the system will automatically release the resources.
1000 tokens/s, not only fast, but also a qualitative change in paradigm
On the scale of trillion parameters (1T), breaking through 1000 tps is not just about making the typewriter faster; it brings about a fundamental subversion of the AI application paradigm.
First, speed itself begins to transform into intelligence. In the past, when faced with difficult problems, you could only "wait for an answer and pray it was correct"; now, within the same waiting time, the model can run dozens of inference paths in parallel (Best-of-N/Tree Search), automatically verify and correct errors in the background, and use "speed" to derive the depth of thinking, directly improving the quality of inference.
Secondly, it has completely liberated the productivity limit of Coding Agent. Previously, when asking AI to write code, developers were often confined by the inference speed and had to sit in front of the screen waiting painfully. However, the ultra-fast inference of 1000 tps has brought about a revolutionary code writing speed and a soaring production efficiency.
Most importantly, trillion-scale models are starting to enter the real-time decision-making closed loop. The millisecond-level "thinking-response" cycle enables the 1T flagship model to seamlessly integrate into time-sensitive scenarios - high-frequency quantitative trading signal generation, instantaneous anti-fraud risk control interception, intelligent bidding, and real-time interactive dialogue.
When this power is injected into life - critical scenarios such as surgical assistance and medical image analysis, the speed of AI is no longer just a measure of efficiency, but a bargaining chip in a race against death. In the operating room, for every second that AI completes lesion analysis and risk prediction ahead of time, the room for doctors to act increases. This makes us deeply convinced that the ultimate significance of speed is not just to boost productivity, but to enable technology to provide a better life for humanity.
Optimal Codesign of Model and System
Achieving an output speed of over 1000 tokens/s for the 1T flagship model is not a breakthrough in a single technology, but rather the result of in-depth collaboration between the MiMo model and TileRT system teams and their pursuit of ultimate codesign. When the current industry pursues similar extreme speeds, it often chooses to take the dedicated hardware route, such as Cerebras' wafer-scale integration (Wafer-Scale) or Groq's custom chip architecture based on pure on-chip SRAM. We chose to implement even more impressive inference speed on general-purpose GPUs through model-system co-design.
On the model side, in response to the bandwidth bottleneck of general-purpose hardware, FP4 quantization was performed, significantly reducing the model size and memory access overhead; meanwhile, an efficient speculative decoding DFlash based on block-level masked parallel prediction was introduced, greatly increasing the Token acceptance length per validation. On the system side, TileRT is perfectly adapted to the dynamic characteristics of the algorithm, customizing a specially optimized compilation engine and compute kernel for the new quantization and speculative decoding processes.Thanks to this ultimate Codesign, we were able to enable a 1T model to exceed an output speed of 1000 tokens/s using only a standard 8-card general-purpose GPU node.
FP4 Quantization
At the scale of trillion parameters (1T), traditional 8-bit (such as FP8/INT8) or even 16-bit inference can lead to extremely high GPU memory usage and memory bandwidth pressure. Reducing the bit width of parameters can directly contribute to the decoding output speed. Therefore, we adopted the industry-standard and almost lossless FP4 (MXFP4[1]) quantization.
However, if FP4 quantization is applied uniformly to the entire model, the accuracy and generalization ability of the model in complex reasoning and logical code often degrade. Given the typical MoE (Mixture of Experts) architecture characteristics of Xiaomi MiMo-V2.5-Pro, its Experts account for the vast majority of the parameters and have the highest tolerance for quantization accuracy. Therefore, we choose to perform parameter FP4 quantization only on the MoE Experts while retaining the original accuracy for other modules. Through such FP4 QAT (Quantization-Aware Training), we have significantly reduced the model size and maximized hardware bandwidth utilization while keeping the overall capabilities of the model basically on par with the original model, as shown in the figure below:
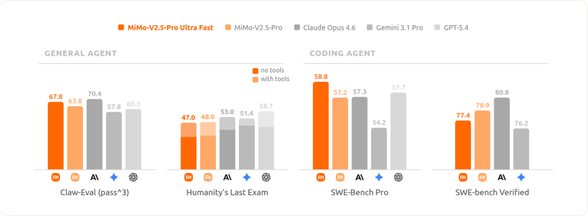
[FP4 vs FP8 Model Comparison]
DFlash Speculative Decoding
Traditional Speculative Decoding relies on a small draft model to "guess" subsequent tokens, which are then verified by a large model. This approach transforms the autoregressive generation that produces 1 token per forward pass into parallel generation of multiple tokens, and the rejection sampling mechanism in the large model verification process ensures that the output quality remains intact.However, its bottleneck lies in the fact that the quality of the draft model determines the acceptance rate, while a stronger draft model brings higher computational overhead, making it difficult to achieve both.
To break this deadlock, we adopted the innovative DFlash block-level masked parallel prediction method [2] in academia: the draft model fills an entire block of masked positions simultaneously in a single forward pass, fundamentally removing the serial constraint of "draft autoregression".
We have implemented and customized this path on MiMo-V2.5-Pro, targeting trillion-scale MoE and long context scenarios. Through the Muon second-order optimizer and model self-distillation, we ensure that small mask blocks can still provide an ideal acceptance rate while compressing the overhead of the draft stage to near the limit:
-
The Draft model fully adopts the Sliding Window Attention (SWA) mechanism, which is naturally aligned with the SWA design of the MiMo-V2 series models. This enables Draft to no longer rely on a complete prefix, and the computing power for a single prediction changes from linearly increasing with the context length to a constant level.
-
During training, the mask signal sampling is offloaded to the local GPU sharding, enabling a single sequence step to generate tens of thousands of independent training signals covering different lengths of context positions, aligning with the long context capabilities of the MiMo-V2 series models while avoiding cross-device communication overhead.
In terms of effectiveness, our parallel prediction speculative decoding has achieved a significant increase in acceptance length in multiple agent and high-value coding scenarios, meaning that the large model can "confirm" more content in one go during each verification; in addition, we limit the mask block size to 8 to reduce verification overhead and improve concurrency, enabling the high acceptance length to be directly translated into high inference throughput:
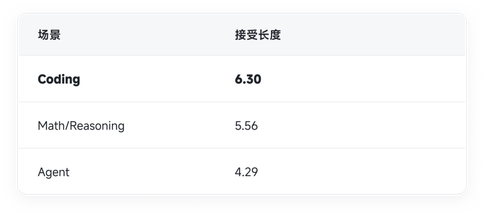
[Acceptable Length of DFlash in Different Scenarios]
In the Coding scenario, the average acceptance length can reach 6.30, and in some samples, it reaches a maximum of 7.14. This means that among the 8 draft tokens per round of verification, 6-7 tokens can be accepted, and the draft pushes the acceptance rate to a level where end-to-end truly benefits while maintaining lightness. We also find that in the general conversation scenario with more divergent semantics and higher uncertainty, the current acceptance rate is not yet high, and we are continuously optimizing the algorithm to explore a higher generalization ceiling.
TileRT Ultra-Low Latency Inference Kernel/System
If the algorithmic reconstruction of MiMo has removed the heavy bandwidth shackles for the trillion and quadrillion models, then the TileRT inference system has directly squeezed the physical potential of general-purpose GPUs to the absolute limit of the microsecond level.
Under the ultra-high frequency operating state of 1000 tokens/s, the lifecycle of a single operator is compressed to the microsecond level, and the "operator boundary" of traditional inference systems has become the core bottleneck - each operator launch, hardware synchronization, and global memory round-trip will interrupt the entire execution flow on the microsecond scale, exposing an obvious "Execution Gap".
Paradigm-level Execution Model Transformation of TileRTAs the underlying infrastructure for ultra-low latency inference, TileRT introduces a brand-new execution model that fundamentally eliminates the execution gaps caused by operator boundaries:
-
Persistent Engine Kernel: Completely abandons the traditional operator-by-operator startup mode, allowing the entire computing pipeline to reside permanently inside the GPU for continuous operation. This enables the system to achieve whole-link continuous prefetching capabilities. While the current tile is still being computed in the Tensor Core, subsequent data has already flowed in advance along the storage architecture, achieving the ultimate overlap of data transfer and computation.
-
Heterogeneous Pipeline Collaboration (Warp Specialization) : At the Tile level, communication, data movement, and tensor computation are more finely physically disassembled. By breaking the original homogeneous serial pace, different Warps (thread bundles) and even the heterogeneous execution domains of the entire GPU can each perform their own duties and collaborate precisely, completely evolving the GPU into a continuously flowing and precisely coordinated heterogeneous execution system.
Deep convergence of software and hardware (Codesign) at the microsecond scaleWhen the underlying execution model pushes hardware performance to its limits, pure runtime optimization begins to hit physical limitations. On this basis, the TileRT system team and Xiaomi MiMo team have carried out in-depth technical co-creation, breaking the original software hierarchical barriers.To ensure that the model behavior perfectly aligns with the continuous advancement of this ultra-low latency execution pipeline, the model layer ultimately adopted an FP4 hybrid quantization strategy targeting MoE Experts and implemented DFlash speculative decoding aligned with SWA on the trillion-scale architecture. TileRT closely coordinated with these algorithmic features and quantization schemes, customizing the underlying compilation engine and compute kernels. Both parties made profound joint engineering trade-offs based on hardware physical limitations, enabling the execution pressure to ultimately achieve a smooth closed-loop within the hardware boundaries.
The emergence of 1000 tokens/s is by no means a coincidence of single-point optimization. It is an inevitable result of the deep convergence and co-evolution of high-level system infrastructure and cutting-edge algorithm models towards each other.
The TileRT team is a cutting-edge system architecture team focused on next-generation AI infrastructure and dedicated to achieving ultra-low latency inference.
The team is committed to driving millisecond-level real-time response of cutting-edge large models in production environments, breaking traditional storage and computing barriers with a brand-new runtime architecture. The team has deduced and implemented a brand-new paradigm-level execution model.
Through full stack breakthroughs in underlying technologies such as persistent kernels, tile pipelines, and heterogeneous collaboration, TileRT has achieved maximum computing power release in the complex heterogeneous computing ecosystem.
As an enabler of core infrastructure, the team actively collaborates with top industry partners to conduct co-design of software and hardware, building a high-performance computing power foundation for the autonomous era that is extremely eager for "ultimate speed".
For more technical details on TileRT, please read:https://www.tilert.ai/blog/breaking-1000-tps-zh.html
More Effect Displays
Create a Snake game in just 10 seconds
Replicate a MacOS system in just 1 minute
Open Source and Outlook
-
We have open-sourced the MiMo-V2.5-Pro-FP4-DFlash checkpoint to HuggingFace, including FP4 quantization weights and DFlash model parameters
-
Welcome the community to use and provide feedback:https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash
-
The ultimate inference support for MiMo-V2.5 is on the way, stay tuned!
MiMo × TileRT, the ultimate co-design of model and system, enables trillion-parameter models to achieve an ultimate inference speed of 1000 TPS.
[1]https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf