Xiaomi MiMo 携手 TileRT|1T 模型首次突破 1000 tokens/s 输出速度
Xiaomi MiMo-V2.5-Pro-UltraSpeed:天下武功,唯快不破
从内燃机时代的第一辆跑车,到突破音障的超音速飞行,人类对速度的渴望,刻在基因里。
AI 推理的速度,同样决定了智能的边界。当模型足够快,它不再只是一个"等待出结果"的工具,而是成为你思维的延伸——实时响应、即时迭代、无缝协作。
今天,MiMo × TileRT 联合发布:Xiaomi MiMo-V2.5-Pro 的 UltraSpeed 模式,让万亿参数的旗舰模型输出速度首次突破 1000 tokens/s。
1000 tokens/s 到底有多快:
限时开放 · 申请制体验
MiMo-V2.5-Pro-UltraSpeed API 同步上线,采用限时体验价,定价为 MiMo-V2.5-Pro 的 3 倍,同时提供输出速度的约 10 倍提升!3 倍价格提升,10 倍输出体验。 (仅支持 API 体验,暂不支持 Token Plan)
本次 MiMo-V2.5-Pro-UltraSpeed 采取申请制限时开放,申请通过的用户可限时接入 API 体验,时间限 2026 年 6 月 9 日 至 6 月 23 日 23:59。
昨晚 MiMo-V2.5-Pro-UltraSpeed 在 X(Twitter)平台发布后的 12 小时内,有超过 3000 家企业及其开发者申请了 UltraSpeed API 的试用名额,行业类别涵盖法律、金融、酒店、通信、物流、互联网、文化传媒、汽车制造等。
👉 申请入口: https://platform.xiaomimimo.com/ultraspeed
由于推理资源紧张,本次试用名额有限,提交申请后不承诺审核时效性和审核通过率;我们将优先审核具备真实业务需求的企业与专业开发者场景,如有 UltraSpeed 相关的大规模商用需求,欢迎联系 business-mimo@xiaomi.com。
💬 Chat 体验(限时免费)
通过审核的用户也可获得限时免费的 Chat 体验(两周开放窗口内有效),体验入口:https://ultraspeed.xiaomimimo.com
为保障资源受限条件下的体验质量与使用公平性,试用服务规则如下:每个账号每日最多成功进入队列 10 次;单次会话时长上限 30 分钟;如会话空闲超过 5 分钟,系统将自动释放资源。
1000 tokens/s,不仅是快,更是范式的质变
在万亿参数(1T)的尺度上,突破 1000 tps 绝不仅仅是打字机变快了,它带来的是 AI 应用范式的底层颠覆。
首先,速度本身开始转化为智能。 过去面对难题你只能“等一个答案并祈祷它是对的”;现在在相同的等待时间内,模型能并行跑数十条推理路径(Best-of-N/Tree Search),在后台自动验证纠错,用“快”衍生出思考的深度,直接提升推理质量。
其次,它彻底解放了 Coding Agent 的生产力极限。 以前让 AI 写代码,受限于推理速度,开发者往往需要坐在屏幕前痛苦地等待。而 1000 tps 的极速推理,带来了颠覆性的代码编写速度与生产效率狂飙。
最重要的是,万亿模型开始进入实时决策闭环。 毫秒级的“思考-响应”循环,让 1T 旗舰模型能够毫无阻碍地接入那些对时间极度敏感的场景——高频量化交易信号生成、瞬时反欺诈风控拦截、智能竞价以及实时交互对话。
而当这种力量被注入到手术辅助、医疗影像分析等生命垂危的场景时,AI的速度,就不再只是衡量效率的指标,而是与死神赛跑的筹码。 在手术台上,AI 每提前一秒完成病灶分析与风险预判,留给医生的处置空间就多一分。这让我们深信,速度的终极意义绝非只是提高生产力,而是让技术为人类提供更好的生活。
模型与系统的极致 Codesign
实现 1T 旗舰模型突破 1000 tokens/s 的输出速度,不是单一技术的突破,而是 MiMo 模型与 TileRT 系统团队深度协作,极致 Codesign 的成果。当前业界在追求类似极致速度时,往往选择走专用硬件路线,例如 Cerebras 的晶圆级集成(Wafer-Scale)或 Groq 基于纯片上 SRAM 的定制芯片架构。而我们选择了在通用 GPU上,通过模型-系统协同设计便实现了更惊人的推理速度。
模型侧针对通用硬件的带宽瓶颈,进行了 FP4 量化,大幅缩减模型体积并减少访存开销;同时引入基于块级 masked 并行预测的高效推测解码 DFlash,大幅提升单次验证的 Token 接受长度。系统侧 TileRT 完美适配算法的动态特性,为全新的量化和推测解码流程量身定制专项优化的编译引擎与计算核。正是凭借这种极致的 Codesign,我们仅用一个标准的 8 卡通用 GPU 节点,便让 1T 模型突破了 1000 tokens/s 的输出速度。
FP4量化
在万亿参数(1T)的尺度上,传统的 8 比特(如 FP8/INT8)甚至 16 比特推理,会带来极其恐怖的显存占用和内存带宽压力。降低参数的比特位宽,可以直接贡献于解码输出速度。因此,我们采用了业界较为通用且验证过几乎无损的 FP4(MXFP4[1])量化。
然而,如果对整个模型“一刀切”地进行 FP4 量化,模型在复杂推理、逻辑代码上的精度和泛化能力往往会遭遇退化。针对 Xiaomi MiMo-V2.5-Pro 典型的 MoE(Mixture of Experts)架构特性,其 Expert 占据了参数的绝大部分,且对量化的精度容忍度最高。因此,我们选择只对 MoE Expert 进行参数 FP4 量化,而对其他模块则保留原有精度。通过这样的 FP4 QAT(量化感知训练),我们在大幅缩减模型体积、榨干硬件带宽的同时,使模型的整体能力与原模型基本持平。如下图所示:
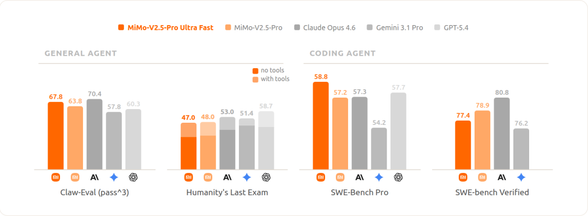
[FP4 vs FP8 模型对比]
DFlash 投机解码
传统的 Speculative Decoding 依赖一个小型 draft 模型来"猜测"后续 tokens,再由大模型验证。这种方法将每次 forward 产出 1 个 token 的自回归生成转换为了多个 token 的并行生成,且大模型验证过程的拒绝采样机制保证了输出质量无损。但是,它的瓶颈在于 draft 模型的质量决定了接受率,而更强的 draft 模型又带来更高的计算开销,两者难以兼得。
为了打破这一僵局,我们采用了学术界创新的 DFlash 块级 masked 并行预测方法[2]:draft 模型在一次前向中同时填出一整块 mask 位置,从根源上解除了"draft 自回归"的串行约束。
我们在 MiMo-V2.5-Pro 上落地了这条路径并进行了定制优化,面向万亿 MoE 与长上下文场景,通过 Muon 二阶优化器与模型自蒸馏保证较小 mask 块仍能够提供理想接受率的同时把 draft 阶段的开销压缩到接近极限:
-
Draft 模型全部采用滑动窗口注意力机制(Sliding Window Attention,SWA),与 MiMo-V2 系列模型自身的 SWA 设计天然对齐。这使得 draft 不再依赖完整前缀,单次预测的算力从随上下文长度线性增长变为常数级。
-
训练时 mask 信号采样下沉到 GPU 本地分片,使一条序列单步即可产出覆盖不同长度上下文位置的数万级独立训练信号,对齐 MiMo-V2 系列模型长上下文能力的同时避免跨设备通信开销。
效果上,我们的并行预测推测解码在多个 agent 和 coding 高价值场景实现了显著的接受长度提升,意味着大模型每次验证都能"一口气"确认更多内容;此外,我们将 mask 块大小限制为 8 以降低验证开销、提高并发水平,使得高接受长度直接转换为高推理吞吐:
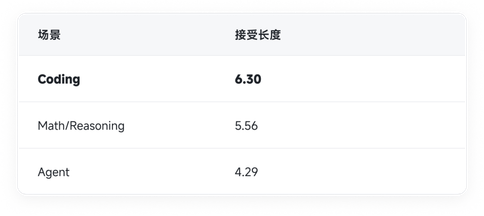
[DFlash 在不同场景下的接受长度]
Coding 场景下可以达到平均 6.30 的接受长度,部分样本中达到了最高 7.14 的接受长度。意味着每轮验证的 8 个 draft token 中可吞下 6-7 个 token,draft 在维持轻量的同时把接受率推到了端到端真正受益的水平。我们也在发现,在语义更发散、不确定性更高的通用对话场景中,当前的接受率还并不高,我们正在持续优化算法,探索更高的泛化上限。
TileRT 超低延迟推理 Kernel/ 系统
如果说 MiMo 的算法重构为千亿与万亿模型卸下了沉重的带宽枷锁,那么 TileRT 推理系统则是直接将通用 GPU 的物理潜能压榨到了微秒级的绝对极限。
在 1000 tokens/s 的超高频运行状态下,单个算子的生命周期被压缩至微秒级,传统推理系统的“算子边界”成为了核心瓶颈——每一次算子启动、硬件同步和全局内存往返,都会在微秒尺度上将整条执行流打断,暴露出明显的“执行间隙(Execution Gap)”。
TileRT 的范式级执行模型变革作为超低延迟推理的底层基础设施,TileRT 引入了全新的执行模型,从根本上消灭了算子边界带来的执行间隙:
-
常驻内核引擎(Persistent Engine Kernel):彻底摒弃传统的逐算子启动模式,让整个计算流水线常驻在 GPU 内部持续流转。这让系统获得了全链路持续预取的能力,在当前 Tile 仍在 Tensor Core 计算时,后续数据已沿着存储架构提前流动,实现数据搬运与计算的极致重叠。
-
异构流水线协作(Warp Specialization):在 Tile 级别将通信、搬运和张量计算进行更精细的物理拆解。打破原有的同构串行步调,让不同的 Warp(线程束)甚至整张 GPU 的异构执行域各司其职、精密协作,将 GPU 彻底演化为一个持续流动、精密协作的异构执行系统。
**微秒级尺度下的软硬件深度收敛(Codesign)**当底层的执行模型将硬件性能推向极限时,纯粹的运行时(Runtime)优化开始触及物理局限。在此基础上,TileRT 系统团队与小米 MiMo 团队展开了深度的技术共创,打破了原有的软件分层藩篱。为了让模型行为完美契合这条超低延迟执行流水线的持续推进,模型层面最终采用了针对 MoE Expert 的 FP4 混合量化策略,并在万亿架构上落地了对齐 SWA 的 DFlash 投机解码。TileRT 紧密配合这些算法特征与量化方案,量身定制了底层的编译引擎与计算核,双方基于硬件物理限制做出了深刻的联合工程权衡,让执行压力最终在硬件边界内平稳闭环。
1000 tokens/s 的诞生,绝不是单点优化的巧合。它是高水平系统基础设施与极致算法模型向着彼此深度收敛、共同演化的必然结果。
TileRT 团队是聚焦于下一代 AI 基础设施、专注于极致低延迟推理的前沿系统架构团队。
团队致力于推动前沿大模型在生产环境中的毫秒级实时响应,以全新的运行时(Runtime)架构打破传统的存储与计算壁垒。团队推演并实现了全新的范式级执行模型。
通过常驻内核(Persistent kernels)、Tile 流水线(Tile pipelines)以及异构协同等底层技术的全栈突破,TileRT 在复杂的异构计算生态中实现了极致的算力释放。
作为核心基础设施的赋能者,团队积极携手行业顶尖伙伴开展软硬件协同设计(Co-design),为迈向极度渴望“极致速度”的自主智能(Autonomous)时代构筑高性能算力底座。
更多 TileRT 技术细节请阅读:https://www.tilert.ai/blog/breaking-1000-tps-zh.html
更多效果展示
仅需 10 秒,做一个贪吃蛇小游戏
仅需 1 分钟,复刻一个 MacOS 系统
开源与展望
-
我们已开源 MiMo-V2.5-Pro-FP4-DFlash checkpoint 到 HuggingFace,包含 FP4 量化权重与 DFlash 模型参数
-
欢迎社区使用和反馈:https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash
-
MiMo-V2.5 的极致推理支持已在路上,敬请期待
MiMo × TileRT,模型与系统的极致 Co-design,让万亿参数模型实现 1000 TPS 的极致推理速度。
[1]https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf